Summary of EPG
In this work, we introduce the $\textbf{Equivariant PushGrasp (EPG)}$ Network, a novel framework for efficient goal-conditioned push-grasp policy learning in cluttered environments. EPG leverages inherent task symmetries to improve both sample efficiency and performance. Specifically, we model the pushing and grasping policies using $SE(2)$-equivariant neural networks, embedding rotational and translational symmetry as an inductive bias. This design substantially enhances the model's generalization and data efficiency. Furthermore, we propose a self-supervised training approach that optimizes the pushing policy with a reward signal defined as the change in grasping scores before and after each push. This formulation simplifies the training procedure and naturally couples the learning of pushing and grasping.
Workflow of EPG

The target object, specified by human instruction, is highlighted with a red mask (e.g., a banana). At each step, the push action direction is represented by an arrow. Our method iteratively predicts and executes push actions to create sufficient space for grasping the target. The final grasp pose is shown as a blue rectangle, with green blocks indicating the gripper's fingers.
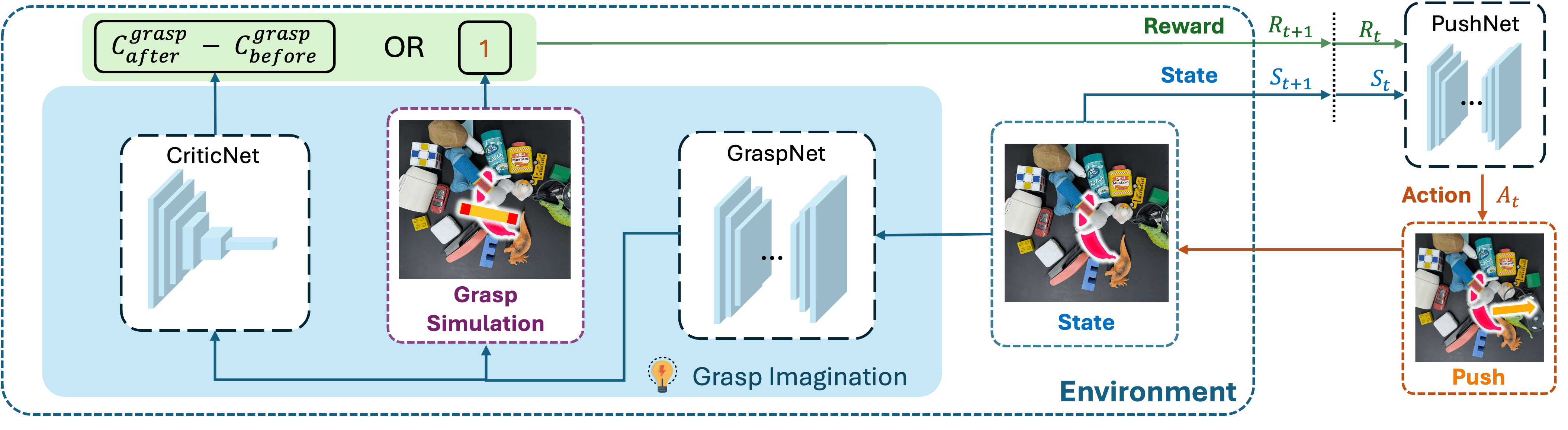
Model Architecture of EPG
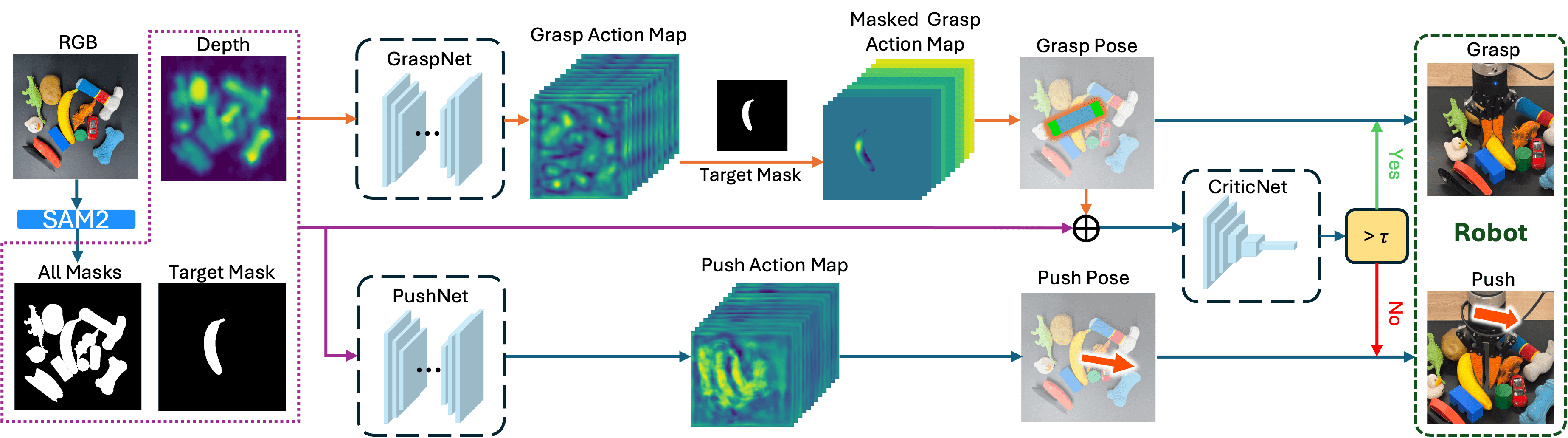
Our model consists of three key components: a CriticNet, a GraspNet, and a PushNet. At each time step, GraspNet and PushNet generate a grasp action and a push action with respect to the target object. CriticNet then evaluates the grasp action by assigning it a score. If the score exceeds a predefined threshold $\tau$ or the maximum number of push attempts is reached, the grasp action is executed. Otherwise, the push action is executed, and the process repeats with an updated observation.
Two-Step Agent Learning
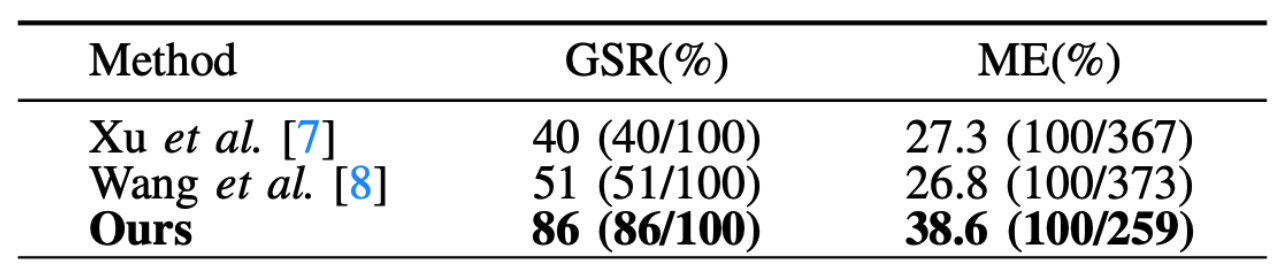
Compared to previous works that rely on complex alternating training between grasp and push networks, we propose a simple two-step training process. First we train a universal, goal-agnostic GraspNet together with a CriticNet that evaluates predicted grasps and returns a score. Then, we use the difference in grasp scores before and after pushing, computed from the CriticNet, as a reward signal to train a goal-conditioned PushNet. This decoupled training strategy eliminates the need for alternating optimization and its scheduling-related hyperparameters, making the training more stable, controllable, and efficient. For more details, please refer to the paper.